EfficientNet
- Improving Accuracy and Efficiency through AutoML and Model Scaling
안녕하세요. 이 포스팅은 EfficientNet review 를 정리한 것으로 PR-168 발표 강의를 기반하고 있습니다. Google에서 ICML2019 학회에 제출한 논문으로 연산비용과 파라미터 수를 낮춰 효율성을 높일 수 있는 방법을 제안하고 있습니다.

Background
ResNet 이후 사람보다 더 좋은 결과를 만들어내게 되었고 CNN을 활용하여 모델을 만드는 관점은 크게 두가지로 보여졌습니다.

FLOPS(FLoating point OPerations per Second) - 초당 부동소수점 연산이라는 의미로 컴퓨터가 1초동안 수행할 수 있는 부동소수점 연산의 횟수를 기준으로 삼는다.(wiki)
- 더 높은 정확도 향상을 위한 방법
- 준수한 정확도를 갖으면서 연산 비용을 낮추기 위한 방법
보통 정확도를 더욱 향상시키기 위해서 모델을 더욱 깊고 넓게 만들거나 입력시키는 이미지의 사이즈를 크게 주는 방법을 사용하였습니다. 하지만, 하드웨어 자원은 한정되어 있으니 한정된 자원을 더욱 효율적으로 활용하기 위해서 연산비용을 낮추면서 준수한 정확도를 내기위해 여러가지 방법들이 제안되었습니다. 이번 포스팅에서 소개할 EfficientNet은 두 마리 토끼를 모두 잡는 방법을 제안하고 있습니다.
Intro.
ConvNets을 Scaling-up하고 widely하게 함으로써 더욱 좋은 결과를 만들수 있게 되었습니다.
- ResNet-18을 ResNet-200으로 layer수를 더욱 늘리면서 정확도를 향상
- GPipe 는 모델을 4배 가까이 키우면서 ImageNet 데이터에 대해서 84.3% top-1 accuary를 달성
일반적으로 ConvNets을 Scaling-up하는 방법에는 크게 3가지 요소를 활용하게 됩니다.
- Depth : Layer 수를 더욱 늘려 층을 깊에 쌓는 것을 의미합니다. (ex, ResNet-50, ResNet-101)
- Width : Filter의 개수(Channel의 개수)를 늘리는 것을 의미합니다. (ex, MobileNet, ShuffleNet)
- Image resolution : 입력 이미지의 해상도(크기)를 키우는 것을 의미합니다.

각 Block들은 Width * Height * Channel 을 Resolution * Channel 의 형태로 표현한 것입니다.
일전의 연구들은 scaling 기법 중에 어떤 것을 늘려야 하는지 마땅한 가이드라인이 없었기 때문에 3가지 요소중 하나를 선택하여 실험을 진행하였습니다. 그래서 기존 방식들에서는 위의 3가지 scaling을 동시에 고려하는 경우가 거의 없었습니다. 그래서 본 논문에서는 3가지 scale을 모두 고려하면서 효율적인 모델을 만들 수 있는 compound scaling방법을 제안하고 있습니다.
Related Work
- ConvNet Accuracy
- ImageNet(Years / Model / top-1 Accuracy / Parameters)
- 2014 / GoogleNet (Szegedy et al., 2015) / 74.8% / 6.8M
- 2017 / SENet (Huang et al., 2018) / 82.7% / 145M
- 2019 / GPipe(Huang et al., 2018) / 84.3% / 557M
- 성능이 향상되면서 동시에 파라미터 수 또한 급증하는 경향을 볼 수 있습니다. 이는 한정된 하드웨어 자원을 효율적으로 사용할 필요성이 필요하다는 견해를 느낄 수 있습니다.
- ImageNet(Years / Model / top-1 Accuracy / Parameters)
- ConvNet Efficiency
- Model comprasion을 통한 모델의 사이즈를 감소시키는 방법들이 제안
- SqueezeNets, MobileNets, ShuffleNets 와 같은 mobile-size의 ConvNets들이 제안
- 최근 MNasNet과 같이 AutoML을 통한 neural architechture search 방법이 제안
- 하지만, 모델을 어떻게 생성할 것인가에 대한 가이드라인이 마땅히 없기 때문에(unclear) 최적의 모델을 찾기위한 design space가 매우 커서 tuning cost가 매우 높은 문제가 있습니다.
- Model Scaling
- ResNet은 depth(layers)를 키우거나 줄여 scale을 조정
- WideResNet, MobileNet은 network width(channels)를 조정
- Input image size(resolution)을 키우는 방법은 정확도 향상에 도움이 되지만 FLOPS의 overhead 문제가 있음
- 어떻게 효율적으로 ConvNets의 scale을 조정하여 efficiency와 accuracy를 높이는 방법이 issue
Problem Formulation
기존의 ConvNets 의 Formulation을 보면 다음과 같습니다.

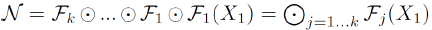
마치 '함성함수' 처럼 연산되게 됩니다.
- $N$ : Convolution Network
- $\ F_i$ : 한 stage에서 반복적으로 수행하는 함수 (ex, skip connection, inception block)
- $\ L_i$ : 한 stage에서 $\ F_i$ 를 몇 번 반복할 것인지 (단순한 operation을 stack해서 반복작업)
일반적으로 $\ F_i$ 는 고정한 채로 $L_i$(length), resolution($H_i$,$Wi$), $C_i$(width) 를 조절하여 최적의 모델을 찾는 과정을 반복하지만, 대부분 실험적인 결과에 의존하고 있기 때문에 design space가 너무 큰 문제점이 있습니다.
그래서 EfficientNet에서는 이러한 Formulation 문제를 개선하여 design space를 줄이기 위해 모델의 scale을 결정하는 3가지 요소를 모두 고려하는 방법을 다음과 같이 제안하였습니다.

- $N(d,w,r) $ : Network scale Factors
- $d\cdot\hat{L}_i$ : depth($d$) ratio에 따라서 Layer($\hat{L}_i$)의 scale을 조정
- $r\cdot\hat{H}_i,r\cdot\hat{W}_i$ : resolution($r$) ratio를 조정하여 scale을 조정
- $w\cdot\hat{C}_i$ : width($w$) ratio를 조정하여 Channel($\hat{C}_i$) scale을 조정
- Memory($N$) 과 FLOPS($N$)는 target_limit을 넘지 않는 것을 조건으로 하고 있습니다. (한정된 자원을 조건)
Scaling Dimensions
Network scale Fators 중 하나씩 선택하여 scale을 조정한 결과를 나타내고 있습니다.

- 네트워크가 증가함에 따라서 accuracy gain이 감소하는 경향을 보이기도 하고 Depth, Width의 경우 Saturation point 에 도달하여 연산량이 증가함에 따라 정확도 향상이 미미한 것을 볼 수 있습니다.
- Width를 조절한 경우 매우 wide하지만 좁은 네트워크 모델의 경우 higher level features를 획득하기 어려운 문제점이 발생합니다.
Observation 1
"어떤 dimension을 scaling 하더라도 accuracy gain이 점점 model이 커짐에 따라서 줄어드는 특성이 나타난다."Compound Scaling
직관적으로 resolution이 커지면 그에 맞게 depth나 width를 늘려야하는 것을 알 수 있습니다. 그러므로 recept field를 비율적으로 맞춰주기 위해서는 더 많은 layer가 필요하고 그에 따라 channel 수가 증가합니다.

- depth와 resolution을 고정하여 width의 scale을 고려하는 것보다 논문에서 제안하는 compound scaling(3가지 요소를 함께 고려하는것)을 하는 것이 더욱 성능이 좋은 것을 나타내고 있습니다.
- depth($r$)와 resolution($r$)의 크기를 함께 키우고 width($w$) scaling을 하는 것이 동일한 FLOPS cost에 대해서 더 빠르게 정확도를 향상시킬 수 있는 것을 알 수 있습니다.
Observation 2
"Network scale Factors 3개의 Dimension을 Scale-Up할 때 Balance를 맞추는 것이 Critical하다"Compound Scaling Method
"Compund Scaling method의 핵심은 $\alpha,\beta,\gamma$ 를 어떻게 찾을 것인가" 입니다. 그에 따라서 다음과 같은 식을 정의하고 있습니다.
$$
depth: d = \alpha^\phi \
$$
$$
width: w = \beta^\phi \
$$
$$
resolution: r = \gamma^\phi \
$$
$$
s.t.\quad\alpha\cdot\beta^2\cdot\gamma^2 \approx 2 \
$$
$$
\alpha\geq1, \beta\geq1,\gamma\geq1
$$
- $\phi$ : user가 같고 있는 resource에 따라 조정하는 hyperparameter
- $\quad\alpha\cdot\beta^2\cdot\gamma^2 \approx 2$ 로 고정하는 이유는 네트워크를 2배, 4배등으로 scalling-up하기 용이하도록 설정된 값
$\alpha$와 $\beta,\gamma$를 지수승을 다르게 한 이유는 연산량에 비례하여 FLOPS를 계산하기 위함입니다.
- 다른 요소를 고정하고 Layer($\alpha$) 수를 2배로 증가시키면 연산량은 2배로 비례하여 증가합니다
- 하지만 channel($\beta$) 수나 input image resolution($\gamma$)을 2배로 증가시키게 되면 연산량은 2의 지수승으로 증가합니다.
- channel은 한 layer에서 layer output 출력이 나갈 때 channel의 계산이 2배가 되므로 x2가 되고 다시 다음 layer input으로 들어가게 되므로 x2가 반복적으로 발생하므로 2의 지수승이 됩니다.
- input image resolution은 이미지의 가로와 세로가 2배고 증가하면 2의 지수승으로 증가하게 됩니다.
- 본 논문에서는 이에 따라서 Total FLOPS가 약 $2^\phi$으로 증가한다고 표현하고 있습니다.
EfficientNet Architecture
논문에서 제안하는 EfficientNet의 기본 Baseline은 MNasNet의 구조를 따르고 있습니다. EfficientNet과의 차이점은 Latency를 고려하지 않았는데, 그 이유는 특정한 하드웨어를 targeting 해서 만드는 것이 아니기 때문입니다.
$$
Optimization,Goal:ACC(m) \times [FLOPS(m)/T]^w \qquad where,w=-0.07
$$
EfficientNet-Bo Baseline Network

- #Layers 개수에 의해서 반복적으로 $MBConv$ 이 반복적으로 생성합니다. (Conv 갯수 뿐만 아니라 resolution이 같아야 같은 Layer가 반복되는 것)
- $MBConv$은 Inverted bottleneck을 갖는 MobileNet V2에서 쓰는 기본 모듈
EfficientNet-B1 to B7
- Step 1
- $\phi$ = 1 로 지정하였을 때 grid search를 통해서 최적의 $\alpha,\beta,\gamma$ 값을 찾습니다.
- $\phi$ 를 여러 값으로 추정할 수 도 있겠지만, 현실적으로 한정된 하드웨어 자원에서 실험적으로 결과를 도출하기에 무리가 있어 $\phi$ = 1 로 최적의 해를 구하여 실험한 것으로 보입니다.
- $\alpha = 1.2, ; \beta = 1.1,; \gamma = 1.15$ 로 하였을 때 가장 좋은 성능
- $\phi$ = 1 로 지정하였을 때 grid search를 통해서 최적의 $\alpha,\beta,\gamma$ 값을 찾습니다.
- Step 2
- $\alpha,\beta,\gamma$ 값을 고정시키고 $\phi$ 을 변경하면서 B1 부터 B7 네트워크를 생성합니다.
- PR-168에서 $\phi$ 의 값이 7일때 B7이 되는지에 대한 내용은 아직 확실치 않은 듯 합니다. (질의응답내용)
- $\alpha,\beta,\gamma$ 값을 고정시키고 $\phi$ 을 변경하면서 B1 부터 B7 네트워크를 생성합니다.
Experiments and Results
Scaling Up MoblieNets and ResNets
본 논문에서는 MNasNet을 기본 Baseline Network로 결정하였는데 MobileNets과 ResNets을 사용하였을 때의 결과도 함께 보여주며 Compound scale Method가 제일 좋은 결과를 도출하는 것을 실험적으로 알려주고 있습니다.

ImageNet Results for EfficientNet
ImageNet 데이터 셋을 기준으로 각 네트워크를 비교한 결과입니다.

- 각 비교 결과는 비슷한 정확도를 갖는 네트워크를 기준으로 Bo 부터 B7까지 정렬한 것 입니다.
- _Ratio-EfficientNet_은 EfficientNet-Bn 을 단위기준으로 하여 파라미터 수와 연산량이 몇 배가 차이나는 지에 대한 비교 결과를 나타내고 있습니다.
- Resolution-ratio과 같은 경우에 Input image size가 128x128, 299x299 등과 같이 고정되어 있으므로 강제로 키워서 입력으로 넣은 것으로 보입니다.
- 맨 마지막 GPipe 와 비교하였을 때는 파라미터 수가 8배 이상 차이나는 것을 확인할 수 있습니다.
Inference Latency Comparsion
모든 실험에 대해서 Latency를 계산하진 않았지만 대표적으로 두 가지 모델에 대해서 추론 속도를 측정한 결과를 나타내고 있습니다.

연산량이 감소함에 따라 속도가 빠르게 증가하는 것을 보이고 있습니다.
$\blacktriangleright$ 파라미터 수가 감소하였다고 하여 무조건적으로 비례하여 Latency가 상승되는 것은 아니라는 견해를 강의 중에 해주셨습니다. 하지만, 파라미터 수를 막대하게 감소시켰기에 그에따라 추론 속도가 증가하는 것이라는 견해도 말씀하셨습니다.
Transfer Learning Results for EfficientNets
Transfer Learning 을 진행하였을 때에도 상당히 좋은 결과를 보이고 있습니다. 특정 데이터 셋에서는 SOTA를 달성하진 못하였지만 대부분 근소한 차이를 보이며 연산량 대비 정확도 측면에서 효율이 매우 좋은 것을 알 수 있습니다.

Discussion

- Network scale Factor 들 중 하나씩 사용하였을 때의 결과와 모두 동시에 고려한 Compund scaling과의 비교 결과입니다.
- 단일 요소를 고려하는 것보다 Compound scaling을 진행하였을 때 결과가 월등히 좋아지는 것을 확인할 수 있습니다.
Class Activation Maps

- Activation Map을 통해서 결과를 확인하였을 때의 결과입니다.
- 결과를 통해서 객체의 특징 잘 activate 하고 있는 것을 알 수 있습니다.